


Marketing-Lehrbuch, Kapitel 4
Marktforschung → Entscheidungsprobleme im Rahmen der Datenerhebung → Auswahlverfahren → Zufallsauswahl (Kapitel 4.2.3.1)
Bei einer Teilerhebung schließt man von der Ausprägung eines Merkmals, das in der Stichprobe erhoben wurde, auf die entsprechende Ausprägung dieses Merkmals in der Grundgesamtheit (z.B. Anteil der Konsumenten, die Marke X verwenden).
Eine solche „Hochrechnung“ weicht jedoch mehr oder weniger stark von der „wahren“ Ausprägung des interessierenden Merkmals in der Grundgesamtheit ab. Diese „wahre“ Ausprägung lässt sich über eine Vollerhebung ermitteln, die aber nur in Ausnahmefällen möglich bzw. sinnvoll ist. Der sogenannte Stichprobenfehler, der auch als Zufallsfehler oder maximale Fehlermarge bezeichnet wird, gibt die zufällige Abweichung der Ausprägung eines Merkmals in der Stichprobe von der „wahren“ Ausprägung des Merkmals in der Grundgesamtheit an. Der Stichprobenfehler wird wie folgt berechnet:
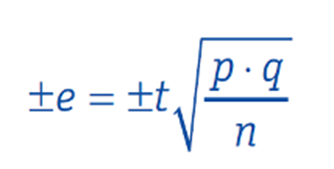
e = Stichprobenfehler, das heißt der Schwankungsbereich (±) in Prozent um den gemessenen Stichprobenwert, in dem der „wahre“ Wert (in der Grundgesamtheit) mit einer bestimmten Wahrscheinlichkeit liegt.
t = Kennziffer für die vorgegebene Sicherheit des Rückschlusses von der Stichprobe auf die Grundgesamtheit (die Wahl von t bestimmt das Signifikanzniveau).
Die folgende Tabelle zeigt, bei welcher Größe von t der »wahre« Wert des Merkmals mit welcher Wahrscheinlichkeit innerhalb des Intervalls p ± e liegt.
| t-Wert | Vertrauenswahrscheinlichkeit (Signifikanzniveau) (in %) |
|---|---|
| 1 | 68,3 |
| 1,96 | 95,0 |
| 2 | 95,5 |
| 3 | 99,7 |
| 3,29 | 99,9 |
p = Anteil der Personen in der Grundgesamtheit, die ein bestimmtes Merkmal aufweisen (z.B. Anteil der Verwender der Marke X).
q = Anteil der Personen in der Grundgesamtheit, die ein bestimmtes Merkmal nicht aufweisen (z.B. Anteil der Nichtverwender der Marke X).
Das Produkt p · q – und damit auch der Stichprobenfehler – ist bei gegebenem Stichprobenumfang am größten, wenn p einen Wert von 50 aufweist. Dieser in Bezug auf den Stichprobenfehler ungünstigste Wert wird immer dann angenommen, wenn p nicht bekannt ist.
n = Stichprobengröße
Folgendes Beispiel verdeutlicht die Berechnung des Stichprobenfehlers: Bei einer Stichprobengröße von n = 400 und der Annahme, dass p = 50 Prozent ist, beträgt der Stichprobenfehler ± 5 Prozent, wenn t = 2 gewählt wird. Demnach liegt der „wahre“ Wert von p, das heißt der Anteil der Verwender der Marke X in der Grundgesamtheit, mit einer Wahrscheinlichkeit von 95,5 Prozent (t = 2) zwischen 45 und 55 Prozent (vgl. Ter Hofte-Fankhauser/Wälty, 2013, S. 50 f.) Das errechnete Intervall wird auch als Konfidenzintervall des Anteilswertes p bezeichnet. Wie die folgende Abbildung zeigt, hängt die Größe des Stichprobenfehlers bei gegebenem Signifikanzniveau einerseits vom Umfang der Stichprobe und andererseits vom Wert p ab.
| Stichprobengröße n | P q | 50 50 | 45 55 | 40 60 | 35 65 | 30 70 | 25 75 | 20 80 | … … |
|---|---|---|---|---|---|---|---|---|---|
| … | … | … | … | … | … | … | … | … | |
| 100 | 10,0 | 9,9 | 9,8 | 9,5 | 9,2 | 8,7 | 8,0 | … | |
| 200 | 7,1 | 7,0 | 6,9 | 6,7 | 6,5 | 6,1 | 5,7 | … | |
| 300 | 5,8 | 5,7 | 5,7 | 5,5 | 5,3 | 5,0 | 4,6 | … | |
| 400 | 5,0 | 5,0 | 4,9 | 4,8 | 4,6 | 4,3 | 4,0 | … | |
| 500 | 4,5 | 4,4 | 4,4 | 4,3 | 4,1 | 3,9 | 3,6 | … | |
| 600 | 4,1 | 4,1 | 4,0 | 3,9 | 3,7 | 3,5 | 3,3 | … | |
| 700 | 3,8 | 3,8 | 3,7 | 3,6 | 3,5 | 3,3 | 3,0 | … | |
| 800 | 3,5 | 3,5 | 3,5 | 3,4 | 3,2 | 3,1 | 2,8 | … | |
| 900 | 3,3 | 3,3 | 3,3 | 3,2 | 3,1 | 2,9 | 2,7 | … | |
| 1000 | 3,2 | 3,1 | 3,1 | 3,0 | 2,9 | 2,7 | 2,5 | … | |
| … | … | … | … | … | … | … | … | … | … |
Die Berechnung des Stichprobenfehlers und des Konfidenzintervalls ist streng genommen nur gestattet, wenn folgende Voraussetzung erfüllt ist: n · p · q ≥ 9 (Bortz/Schuster 2010, S. 104 f.). Sie ist im vorliegenden Beispiel gegeben, da gilt: 400 · 0,5 · 0,5 = 100. Der Stichprobenfehler kann nicht nur für prozentuale Verteilungen, sondern auch für Stichprobenmittelwerte von metrischen Daten berechnet werden (Homburg, 2015, S. 323 ff.).

Zusatzmaterial zu den einzeln Kapiteln:
3-2: Telekom-Werbung – Bedeutung von Spiegelneuronen für emotionale Reaktionen
3-4: Messung impliziter Einstellung mittels implizitem Assoziationstest (IAT)
3-6: Subjektive Wahrnehmung: Sind zwei Tische identisch oder nicht?
3-7: Das Auge isst mit: Die optische Wahrnehmung beeinflusst unser Hungergefühl
3-8: Febreze: Bedeutung habitualisierter Entscheidungen für das Marketing
4-2: Operationalisierung und Messung der Umweltorientierung von EU-Bürgern
4-4: Berechnung des Stichprobenfehlers bei der Zufallsauswahl
4-5: Screening-Fragebogen zur Realisierung einer vorab definierten Stichprobe
4-6: Konzeption eines Gesprächsleitfadens für eine qualitative Befragung
4-7: Beobachtung des individuellen Essverhaltens im „Restaurant der Zukunft“
4-8: Produktpositionierung: Positionierung einer Smartphone-Marke im Wettbewerbsumfeld
7-1: Kindle Fire – Beeinflussung der Wahrnehmung des Nettonutzens durch Werbung
7-2: Ermittlung des optimalen Stromtarifs mittels Choice-Based-Conjointanalyse
7-4: Beeinflussung der wahrgenommenen Preisgünstigkeit durch Umbrella Pricing
7-7: Hohe Attraktivität privater Finanzierungs- und Leasingangebote für Autos
8-1: Produktpositionierung: Code-Analyse des Markenauftritts zweier Sektmarken
8-12: Werbewirkungsanalyse digitaler Kommunikationsinstrumente
8-3: Die Macht der Megatrends und die Zukunft von Sicherheit und Qualität
8-4: Erfolgreiche und nicht erfolgreiche Social-Media-Kampagnen
8-5: Guerilla-Kommunikation: Nutzung eines Neonazi-Aufmarsches für eine gute Sache
Sie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf den Button unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Weitere InformationenSie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen



Studien-Service-Zentrum
+49 3631 420-222
Haus 18, Ebene 1, Raum 18.0105